|【退出】
从Hadoop到Spark的架构实践
2015-08-28 程序员杂志
当下,Spark已经在国内得到了广泛的认可和支持:2014年,Spark Summit China在北京召开,场面火爆;同年,Spark Meetup在北京、上海、深圳和杭州四个城市举办,其中仅北京就成功举办了5次,内容更涵盖Spark Core、Spark Streaming、Spark MLlib、Spark SQL等众多领域。而作为较早关注和引入Spark的移动互联网大数据综合服务公司,TalkingData也积极地参与到国内Spark社区的各种活动,并多次在Meetup中分享公司的Spark使用经验。本文则主要介绍TalkingData在大数据平台建设过程中,逐渐引入Spark,并且以Hadoop YARN和Spark为基础来构建移动大数据平台的过程。
初识Spark
作为一家在移动互联网大数据领域创业的公司,时刻关注大数据技术领域的发展和进步是公司技术团队必做的功课。而在整理Strata 2013公开的讲义时,一篇主题为《An Introduction on the Berkeley Data Analytics Stack_BDAS_Featuring Spark,Spark Streaming,and Shark》的教程引起了整个技术团队的关注和讨论,其中Spark基于内存的RDD模型、对机器学习算法的支持、整个技术栈中实时处理和离线处理的统一模型以及Shark都让人眼前一亮。同时期我们关注的还有Impala,但对比Spark,Impala可以理解为对Hive的升级,而Spark则尝试围绕RDD建立一个用于大数据处理的生态系统。对于一家数据量高速增长,业务又是以大数据处理为核心并且在不断变化的创业公司而言,后者无疑更值得进一步关注和研究。
Spark初探
2013年中期,随着业务高速发展,越来越多的移动设备侧数据被各个不同的业务平台收集。那么这些数据除了提供不同业务所需要的业务指标,是否还蕴藏着更多的价值?为了更好地挖掘数据潜在价值,我们决定建造自己的数据中心,将各业务平台的数据汇集到一起,对覆盖设备的相关数据进行加工、分析和挖掘,从而探索数据的价值。初期数据中心主要功能设置如下所示:
1. 跨市场聚合的安卓应用排名;
2. 基于用户兴趣的应用推荐。
基于当时的技术掌握程度和功能需求,数据中心所采用的技术架构如图1。
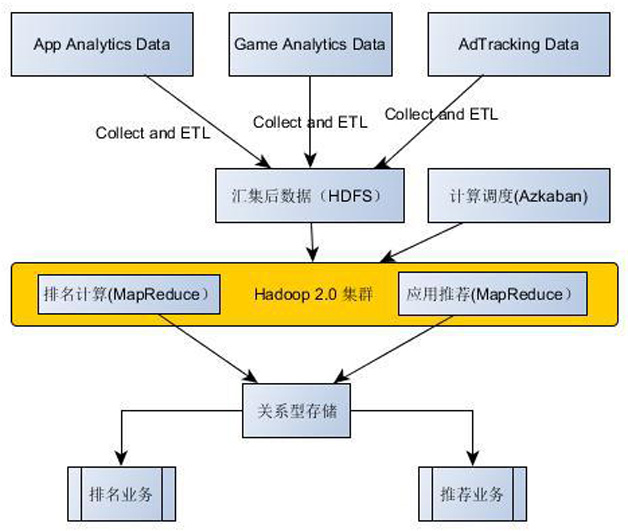
图1 基于Hadoop 2.0的数据中心技术架构
整个系统构建基于Hadoop 2.0(Cloudera CDH4.3),采用了最原始的大数据计算架构。通过日志汇集程序,将不同业务平台的日志汇集到数据中心,并通过ETL将数据进行格式化处理,储存到HDFS。其中,排名和推荐算法的实现都采用了MapReduce,系统中只存在离线批量计算,并通过基于Azkaban的调度系统进行离线任务的调度。
第一个版本的数据中心架构基本上是以满足“最基本的数据利用”这一目的进行设计的。然而,随着对数据价值探索得逐渐加深,越来越多的实时分析需求被提出。与此同时,更多的机器学习算法也亟需添加,以便支持不同的数据挖掘需求。对于实时数据分析,显然不能通过“对每个分析需求单独开发MapReduce任务”来完成,因此引入Hive 是一个简单而直接的选择。鉴于传统的MapReduce模型并不能很好地支持迭代计算,我们需要一个更好的并行计算框架来支持机器学习算法。而这些正是我们一直在密切关注的Spark所擅长的领域——凭借其对迭代计算的友好支持,Spark理所当然地成为了不二之选。2013年9月底,随着Spark 0.8.0发布,我们决定对最初的架构进行演进,引入Hive作为即时查询的基础,同时引入Spark计算框架来支持机器学习类型的计算,并且验证Spark这个新的计算框架是否能够全面替代传统的以MapReduce为基础的计算框架。图2为整个系统的架构演变。
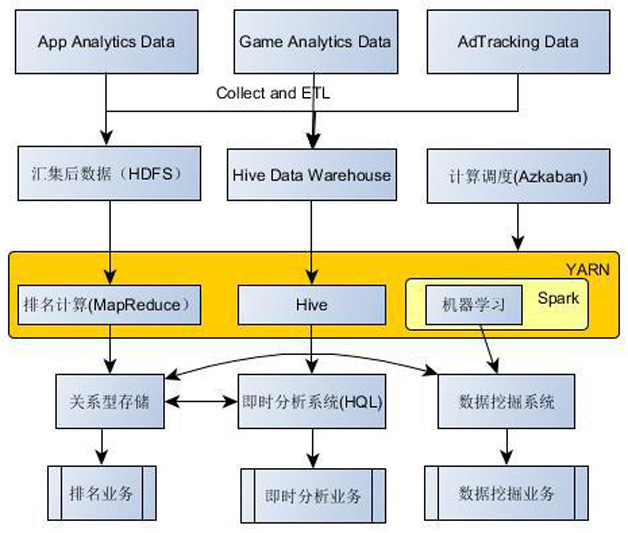
图2 在原始架构中测试Spark
在这个架构中,我们将Spark 0.8.1部署在YARN上,通过分Queue,来隔离基于Spark的机器学习任务,计算排名的日常MapReduce任务和基于Hive的即时分析任务。
想要引入Spark,第一步需要做的就是要取得支持我们Hadoop环境的Spark包。我们的Hadoop环境是Cloudera发布的CDH 4.3,默认的Spark发布包并不包含支持CDH 4.3的版本,因此只能自己编译。Spark官方文档推荐用Maven进行编译,可是编译却不如想象中顺利。各种包依赖由于众所周知的原因,不能顺利地从某些依赖中心库下载。于是我们采取了最简单直接的绕开办法,利用AWS云主机进行编译。需要注意的是,编译前一定要遵循文档的建议,设置:
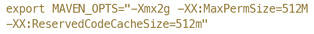
否则,编译过程中就会遇到内存溢出的问题。针对CDH 4.3,mvn build的参数为:

在编译成功所需要的Spark包后,部署和在Hadoop环境中运行Spark则是非常简单的事情。将编译好的Spark目录打包压缩后,在可以运行Hadoop Client的机器上解压缩,就可以运行Spark了。想要验证Spark是否能够正常在目标Hadoop环境上运行,可以参照Spark的官方文档,运行example中的SparkPi来验证:

完成Spark部署之后,剩下的就是开发基于Spark的程序了。虽然Spark支持Java、Python,但最合适开发Spark程序的语言还是Scala。经过一段时间的摸索实践,我们掌握了Scala语言的函数式编程语言特点后,终于体会了利用Scala开发Spark应用的巨大好处。同样的功能,用MapReduce几百行才能实现的计算,在Spark中,Scala通过短短的数十行代码就能完成。而在运行时,同样的计算功能,Spark上执行则比MapReduce有数十倍的提高。对于需要迭代的机器学习算法来讲,Spark的RDD模型相比MapReduce的优势则更是明显,更何况还有基本的MLlib的支持。经过几个月的实践,数据挖掘相关工作被完全迁移到Spark,并且在Spark上实现了适合我们数据集的更高效的LR等等算法。
![京网文[2017]10376-1180号](http://www.edu.cn/images/indexnew/www1024.jpg){kind=link}